- Published on
Engineering a Scalable GPU Accelerated Machine Learning Cloud Environment
- Authors

- Name
- Mae
Introduction
Much of the reason that deep learning has become popular and successful in recent years is the availability of vector processing with flexible GPU compute. As a Machine Learning Research Group we utilize GPU acceleration to conduct all of our experiments. As a part of the Tutorials for the Canada-France-Iceland Workshop on Machine Learning and Computer Vision we needed a GPU accelerated environment that could be used by 50 or more people.
Terms
For clarity and brevity I've provided definitions for some terms I use here:
- Server: an instance of a Jupyter Notebook
- Hub: the gateway, manager, machine that hosts the JupyterHub application and other services
- Machine: a "physical" machine, such as a virtual private server hosted on EC2
- Container: a single instance of the Docker image
- Image: a static binary that represents a containerized environment in the Docker terminology
Architecture
Jupyter based notebooks utilize Python kernels and are a superset of capabilities of the Python interpreter. JupyterHub is a software that utilizes individual Jupyter notebook instances in order to offer an isolated environment for each user. Jupyterhub can use modular spawners in order to create these instances. The most basic spawner uses process isolation on a single machine. For our purposes we wanted to allow each user in our tutorial to have access to their own GPU, or at least, a slice of one. This prevents us from using a single machine since we cannot have 50+ users using GPUs on one machine.
To this end we opted to use different machines and link them all back to the main host in a star topology. In order to manage and distribute the instances we utilized Docker Swarm; which can be considered the more simple version of Kubernetes. In this pattern Docker Swarm managed services which were unique for each user and spawned with the name jy-<username>. The username is from the users Github. We created a new organization to add users to that we could authenticate against. Then, OAuth was utilized to manage the authentication. A simplified diagram below gives an overview of the design, redundant connections are removed for readability.
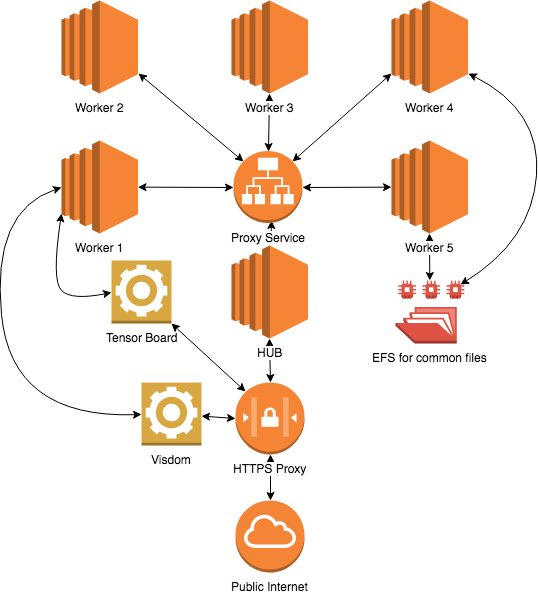
JupyterHub manages proxying request to the different host, all applications in our model were run by Docker Swarm, the JupyterHub, Tensorboard, Visdom, and Caddy reverse HTTPS proxy services were all restricted to this host as well so they were accessible from a single gateway. An interesting thing to note here is that because JupyterHub was using the hosts Docker runtime it was controlling the spawning of other containers from within another container. This is actually a fairly common trick that I've employed in the past to run an application that can run arbitrary untrusted code from users.
Using Docker Swarm for our images also allows us to make changes to the so called "singleuser" Docker image. The JupyterHub team designed a Docker container that was suitable as a base. Therefore we added the requisite libraries to image. This included things like Tensorflow and Pytorch packages managed with Conda. In all, the Docker image was used ended up being a whopping 14GB, which is unusual for Docker images but was required for our purposes. Two Kernels were offered, a Tensorflow and a Pytorch Kernel. The kernels were incompatible with each other as they both depended on different versions of Numpy.
The Docker images required Nvidia runtimes in order to support GPU acceleration from Pytorch and Tensorflow. Installing these libraries gave access to the shared libraries that allow Pytorch and Tensorflow to communicate with the GPUs. Much of the time spent setting up the images is installing various Nvidia runtimes and downloading Python packages. Because we are using Nvidia GPUs we need to use a different Docker runtime as well. To do this, we simply download a Nvidia enabled version of Docker which allows the Docker containers under this runtime to access the GPUs. Which - in vanilla Docker - is not enabled as the Docker runtime isolation prevents access of hardware on the host typically.
Tutorial Files
We used Elastic File Storage (EFS) as a shared directory for the participants to access shared files. This also allowed us to move quicker, letting our tutorial designers change their files and retest them within minutes instead of rebuilding the image with the new tutorial files (which can take up to a half hour). EFS also let us use Tensorboard which uses file based Inter Process Communication (IPS). EFS was mounted as either read-only or read-write in the Docker container as necessary to accomplish this as the users of the Docker image had local root (meaning they could run sudo as necessary and download new packages, or delete their own container if they wanted) and we therefore had to prevent the users from deleting shared tutorial files. This also allowed us to cache data files upwards of 1GB that all the participants needed but would be tedious to download themselves.
We wrote a very small program that constantly polled a Github repo to pull new tutorial files. Therefore, the tutorial writers could make edits locally, push to the repo, and the repo would be pulled to the server overwriting the files. To allow editing of the read-only files the files are copied to a user writable path once the Docker container (AKA JupyterHub server, or just server, in this case) restarts. This also means that users could restore the default configuration by simply restarting their Docker container from within JupyterHub.
Run Fast Break Things (Workers)
One of the principals of this environment is that worker machines should be ephemeral. Primarily, this is due to the cost of the machines on AWS that have GPUs. [The p2.8, p2.16xlarge machines on AWS cost 14.40 an hour. The more time we can have these machines offline, the more money we save. Therefore, the entire process of setting up one of the worker nodes was automated, including access the master server to connect to the Docker Swarm.
New machines added to the Swarm need only be created from a simple template in AWS (which connects them to the EFS, enables my SSH keys and sets the security profile), copy the files from my workstation (or any other worker), then run sudo ./setup.sh. Once complete the worker will be ready to accept new instances.
The setup procedure does many things, the primary are as follows:
- Allocates memory for tmpfs (temp file system, AKA memory disk) of half the available physical memory. This was simply because we had an excessive amount of memory available as part of the EC2 instance but extra disk space would be extra costs.
- Adds the current user to the Docker group so we do not need sudo for
dockercommands - Download/Install the Docker runtime
- Install the Nvidia drivers
- Download/Install the Nvidia Docker Runtime
- Connects via SSH to the Docker Swarm using a provided SSH key
- Generates resources for the Docker runtime for each GPU available on the machine, it provides 3 resources for each physical GPU by creating extensions of the GPU name with numbers (GPU-ABCD, GPU-ABCD-2, GPU-ABCD-3)
- Therefore each GPU can be shared with 3 Docker containers. Because the GPUs have 12GB of memory we can share them if we know they wont use more that 4GB
- An environment variable gets set in the Jupyter server when it starts called
$DOCKER_RESOURCE_GPUwe can use this to create our$CUDA_VISIBLE_DEVICESvariable, we simply strip take anything before the last -, this is done in the startup script of each container
- Modifies the Docker Systemd Unit to reference these resource
- Restarts Docker
- Downloads the prebuilt single user Docker image from the repository
This whole procedure takes roughly 5 minutes and runs (almost) without intervention. Because of it's repeatable setup sequence it also makes repair easy. At times if a machine became unresponsive, instead of taking time to figure out what went wrong a new machine can replace it.
Hub
The Hub, and corresponding machine was configured to handle proxying, HTTPS, swarm coordination, polling Github, and the registry among others already mentioned. Because our image was 14GB and took a long time to build it was beneficial to host a local repository of Docker images. The Hub managed this role and the machines needed to trust the Hub. Therefore, TLS certificates were generated and distributed with the workers.
The Hub also had all the Dockerfiles on it, which are the scripts that generate Docker images. Some, like Tensorboard and Visdom were simple where as others, like JupyterHub itself were more complicated. The JupyterHub image was the most important image of this whole project.
SwarmSpawner
Since we are using Docker Swarm we use the SwarmSpawner class from the dockerspawner repo. Unfortunately there was a small bug with regard to this class based on the operation of Docker-py that had to be patched. It also seems that Docker Swarm is not well maintained compared to other spawners. We had to patch to swarmspawner.py due to an API change in docker-py, or Docker.
JupyterHub Configuration
I this section I will point out a couple useful configuration settings, the full file will be released later.
# Listen on all interfaces
c.JupyterHub.hub_ip = '0.0.0.0'
# Switch to our SwarmSpawner
c.JupyterHub.spawner_class = 'dockerspawner.SwarmSpawner'
# Timeout for the server start
c.Spawner.http_timeout = 90
# The image we actually want to use instead of the default
c.SwarmSpawner.image = 'ip-172-31-13-169.us-east-2.compute.internal:5000/singleuser-torch-nvidia'
# Required to allocate a GPU resource to the Docker container
c.SwarmSpawner.extra_resources_spec = {
'generic_resources': {
"gpu": 1
}
}
# More fine grain volume control, every machine had /efs pointing
# to the same Elastic File System (efs)
c.SwarmSpawner.volumes = {
'/efs/CFIW-Tutorials': {
'bind': '/home/jovyan/shared/CFIW-Tutorials',
'mode': 'ro'
},
'/efs/dataset': {
'bind': '/home/jovyan/shared/dataset',
'mode': 'rw'
},
'/efs/internal': {
'bind': '/home/jovyan/shared/internal',
'mode': 'rw'
},
'/efs/persistant': {
'bind': '/home/jovyan/shared/persistant',
'mode': 'rw'
},
}
# Reference to some of the below
# from https://github.com/compmodels/jupyterhub/blob/master/jupyterhub_config.py
from oauthenticator.github import GitHubOAuthenticator
c.JupyterHub.authenticator_class = GitHubOAuthenticator
c.MyOAuthenticator.oauth_callback_url = os.environ['OAUTH_CALLBACK_URL']
c.MyOAuthenticator.client_id = os.environ['OAUTH_CLIENT_ID']
c.MyOAuthenticator.client_secret = os.environ['OAUTH_CLIENT_SECRET']
# White/allow listing, allows ENV parameterization via Docker Cloud stack in csv
c.GitHubOAuthenticator.github_organization_whitelist = os.environ['ALLOWED_ORG'].split(',')
c.GitHubOAuthenticator.scope = ['read:org']
Conclusions
Orchestrating this was and is difficult, on July 12 we hosted more than 50 people simultaneously giving them access to GPU accelerated capabilities on 3 machines which cost us $370 (USD) including all the setup/configuration/development time and the 8 hour tutorial.
Configuring this system took the better part of week, with much of the work after that point was working with the tutorial developers to ensure that the Docker images had the libraries/software they desired.
There were a few problems, mostly related Github organization signups (they are rate limited, make sure to talk to Github in advance if you want to use an organization as an auth source!) and initially a machine was not accepting new servers. Luckily due to our ability to break things fast we were able to bring the whole system up 5 minutes before the first tutorial entered a interactive component.
Future version would be based on Kubernetes which has better support over Docker Swarm. In the future I would like to release the files I created to make the environment as a guideline on how to set it up. I conjecture that in the upcoming months the software we depend on for this environment will change (Pytorch, Tensorflow, Docker, JupyterHub, Nvidia drivers) and break the scripts and therefore require some maintenance.
Acknowledgements
Thanks to Amazon AWS for granting Vector Institute service credits which we used in the making of this project.